HTMLパーサー「Nokogiri」
RubyのHTMLパーサーとしては"Nokogiri"というライブラリがよく使われています。
- RubyGems nokogiri | RubyGems.org | your community gem host
- 公式チュートリアル Tutorials - Nokogiri 鋸
インストールは gem install nokogiri などとしてください。まずURLをopenしてNokogiriドキュメントを生成してみます。
文字列として読み込んだHTMLをパースしてNokogiri::HTML::Documentオブジェクトを作成しています。
Nokogiri::HTML::Documentが継承しているNokogiri::XML::Nodeは要素検索のためのメソッドを持っています。たとえばNokogiri::XML::Node#atはセレクタでヒットした最初の要素(Element)を返すメソッドです。
また、Nokogiri::XML::Node#cssやNokogiri::XML::Node#xpathはヒットした要素すべてをNokogiri::XML::NodeSetにまとめて返します。例としてAllAboutトップページのメイン記事リストから、記事タイトルとリンク先URLをまとめて抜き出して出力してみます。
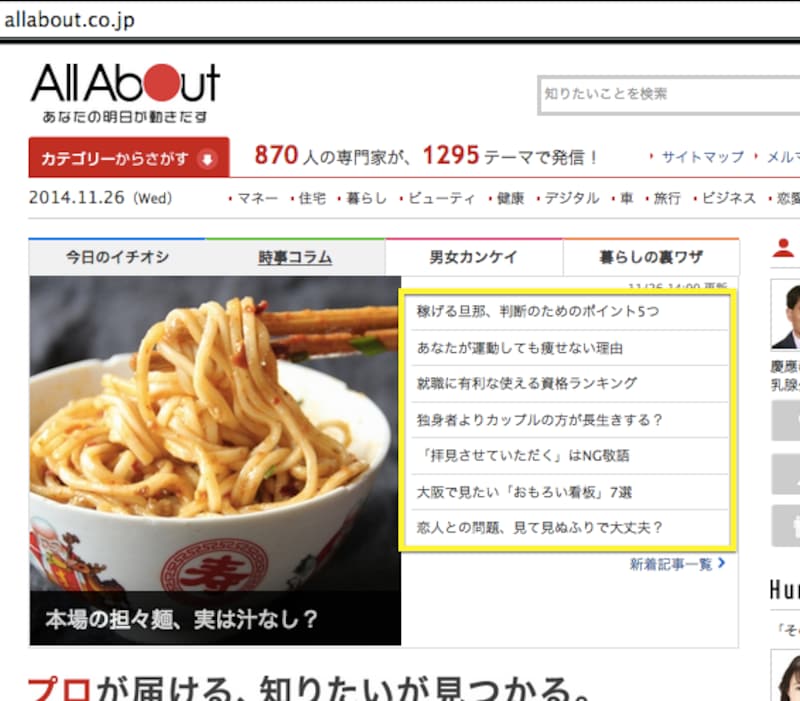
Nokogiri::XML::NodeSetをeachで回した個々のNokogiri::XML::Element(li)に対してtextメソッドで表示テキストを、atで1階層降りた先のattrでhref属性値を取得しています。
次回
今回の記事で、WebのHTMLを取得・パースする方法を紹介しました。単純なHTMLだけならNokogiriで大抵のことは出来るのですが、フォームに値を入れて送信したり(ログイン操作含む)JavaScriptを実行したりと高度なことをやるには向いていません。
そこで、次回の記事ではRubyプログラムでブラウザを制御し、実際にユーザが操作しているのと同じ条件でWebからデータを抽出する方法を紹介します。